
Adaptive Learning Models for Efficient and Standardized Archival Processes
Project Title: Adaptive Learning Models for Efficient and Standardized Archival Processes
Duration
January 2020 – “Ongoing”
Institution
Carl Albert Congressional Research and Studies Center Archives
Project Overview
This project addresses the increasing demands placed on archival systems by large-scale digitization efforts and the complex metadata requirements that accompany them. By developing adaptive learning pipelines, the project enhances efficiency, accuracy, and repeatability in managing digitized historical documents, especially those relevant to American Indian policy, congressional records, and tribal sovereignty.
The model extracts meaningful metadata and enriches archival content using Natural Language Processing (NLP) and machine learning in an iterative, feedback-controlled environment.
Technical Innovation
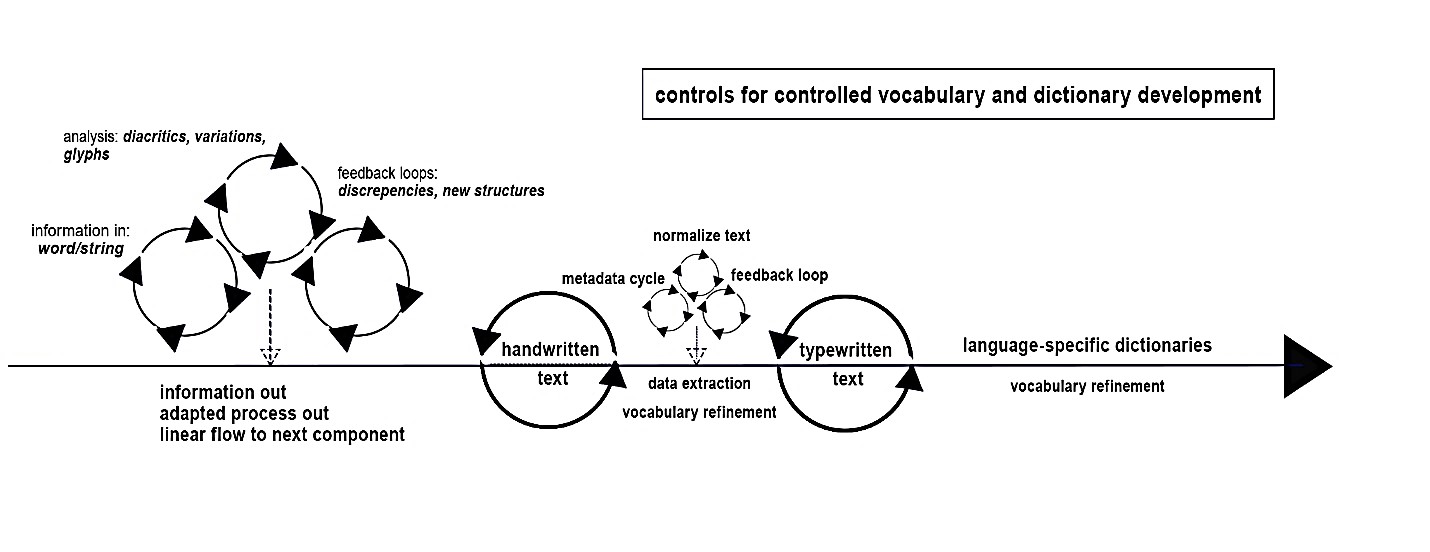
A core innovation of this project is its adaptive loop system that combines multiple modules:
- Preprocessing: Automated OCR cleanup, diacritic analysis, format normalization
- Text Extraction & Entity Recognition: Using AWS Textract, spaCy, and custom models
- Controlled Vocabulary Matching: Real-time lookup against dynamic dictionaries
- Feedback Loops: Enables metadata correction and training model refinement
- Contextual Matching Algorithms: Enables inference for names, tribes, themes
Tools & Technologies
- NLP Libraries: spaCy, TextBlob, NLTK
- OCR and Text Processing: AWS Textract, Tesseract, Gensim
- Machine Learning: Torch, Transformers
- Python APIs: OpenAI, boto3, re, os, pandas
- Custom Classifiers: For tribal affiliation, government functions, correspondence metadata
- Feedback Loop Engines: Performance-aware batch revision triggers
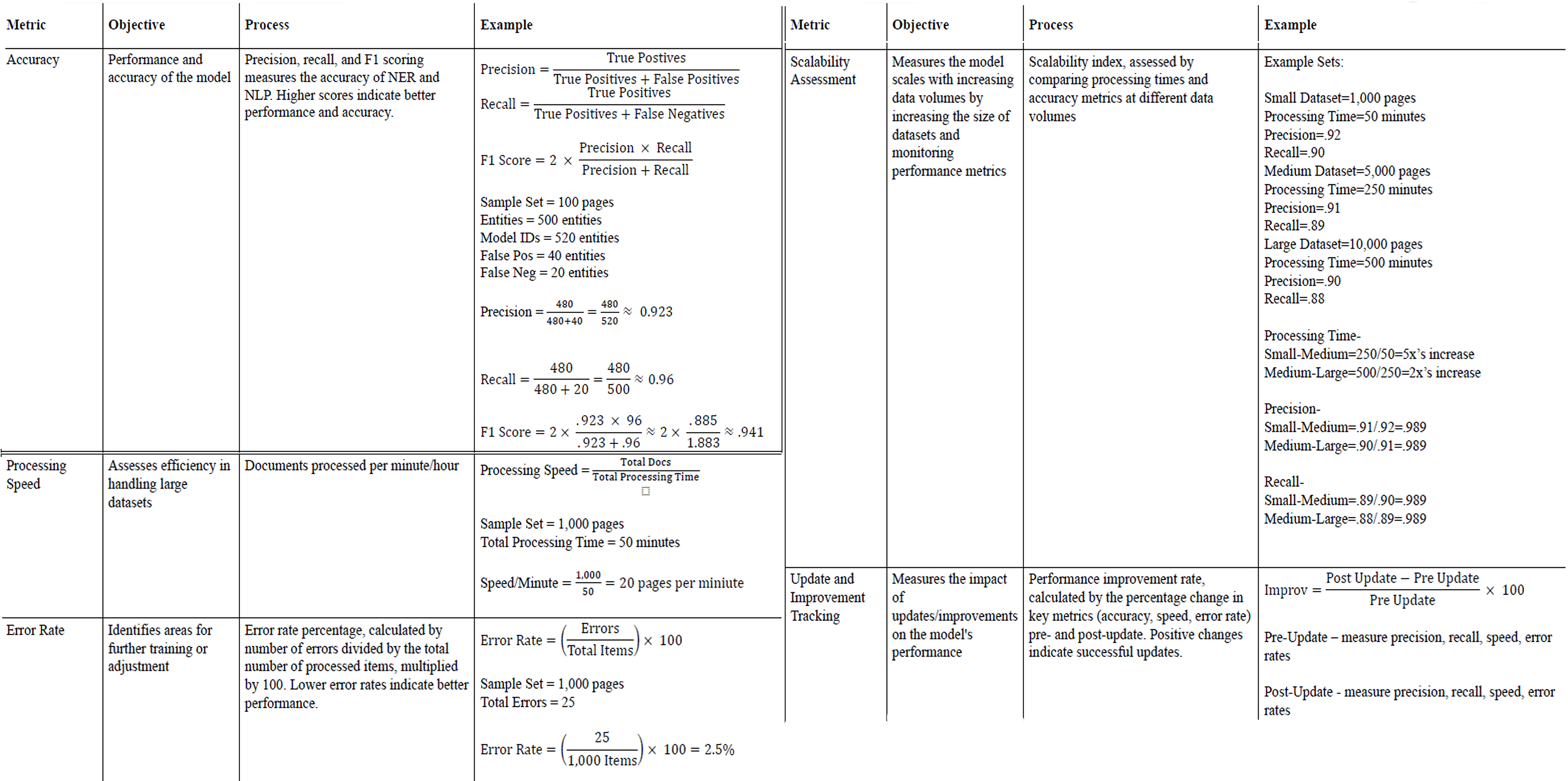
Metrics and Performance
| Metric | Purpose | Example |
|---|---|---|
| Accuracy | Evaluate model precision and recall | F1 Score ≈ 0.941 on 100-page test set |
| Speed | Pages processed per minute | 20 pages/minute on 1,000-page batch |
| Error Rate | % of incorrect assignments | 2.5% on 1,000 document test case |
| Scalability | Handles small to large datasets dynamically | Maintains >0.88 F1 score on 10,000-page loads |
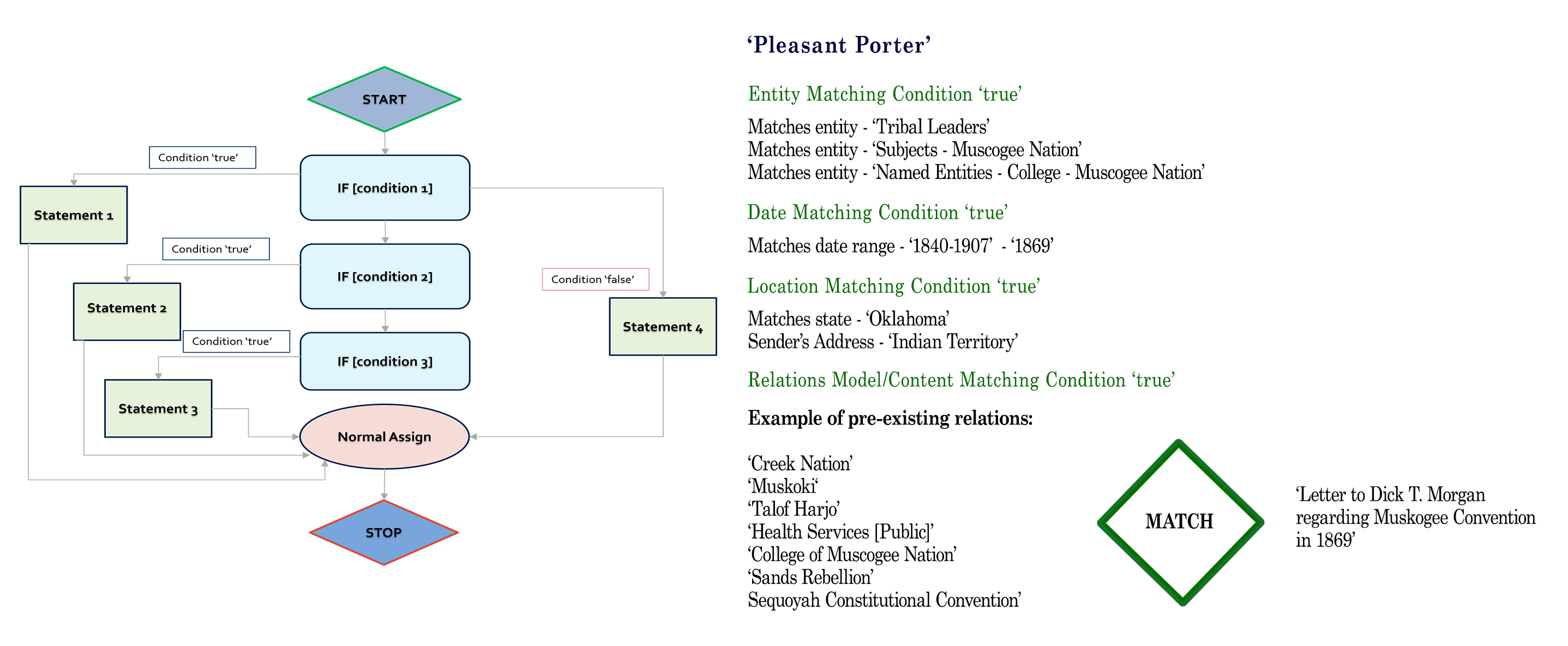
Use Case: “Pleasant Porter” Entity Assignment
This example illustrates how the adaptive model accurately linked a historical reference to Pleasant Porter with the correct tribe, region, and congressional records—without direct keyword matches—by triangulating date, sender location, and prior content relationships.
Resources and Tribal Authority Integration
The project integrates language-specific dictionaries and subject matchers, including:
- Tribal Directories
- Historic Treaties
- Language Dictionaries
- Culturally significant terminology mapping
Outcomes
- Created standardized metadata for over 75,000 records
- Developed 3 evolving model pipelines tested on real collections
- Automated tribal recognition and subject assignment with high accuracy
- Released public training materials and scripts via GitHub
- Framework adopted by the Congressional Portal Project and others