
Digital Archives and Content Platform Development
Project Title: Digital Archives and Content Platform Development
Duration
August 2018 – “Ongoing”
Institution
Carl Albert Congressional Research and Studies Center Archives
Project Overview
This foundational project transformed the Center’s digital archive from a modest collection of 118 digital files into a robust, scalable platform housing over 586,000 digital assets, including:
- Text (document, bound ledgers, maps, books, etc.)
- Photograph images (negatives, positives, slides)
- Audio recordings (antiquated format specialization)
- Video content (antiquated format specialization)
The platform was designed to support long-term preservation, accessibility, and scholarly research.
Technical Innovation
To manage and process this vast and diverse dataset, I developed and implemented custom adaptive learning models. These models enabled:
- Automated metadata extraction
- Content classification and tagging
- Format normalization
- Search optimization
This approach significantly reduced manual labor and improved the discoverability and usability of archival materials.
Tools & Technologies
- Machine Learning: Custom adaptive models
- Digital Asset Management: Automated migration, preservation migration, security management
- Metadata Standards: Dublin Core, EAD, METS, PREMIS, PBCore, MARC, EBUCore, WARC, CAC+
- Storage & Access: AWS (S3, Glacier, Storage Gateway) and Google Cloud (Storage, Transfer, server-side encryption, gsutil), local servers
Outcomes
- Archive grew from 118 to over 586,000+ files
- Improved access for researchers, educators, and the public
- Created a scalable model for future digital preservation projects
Working Platform
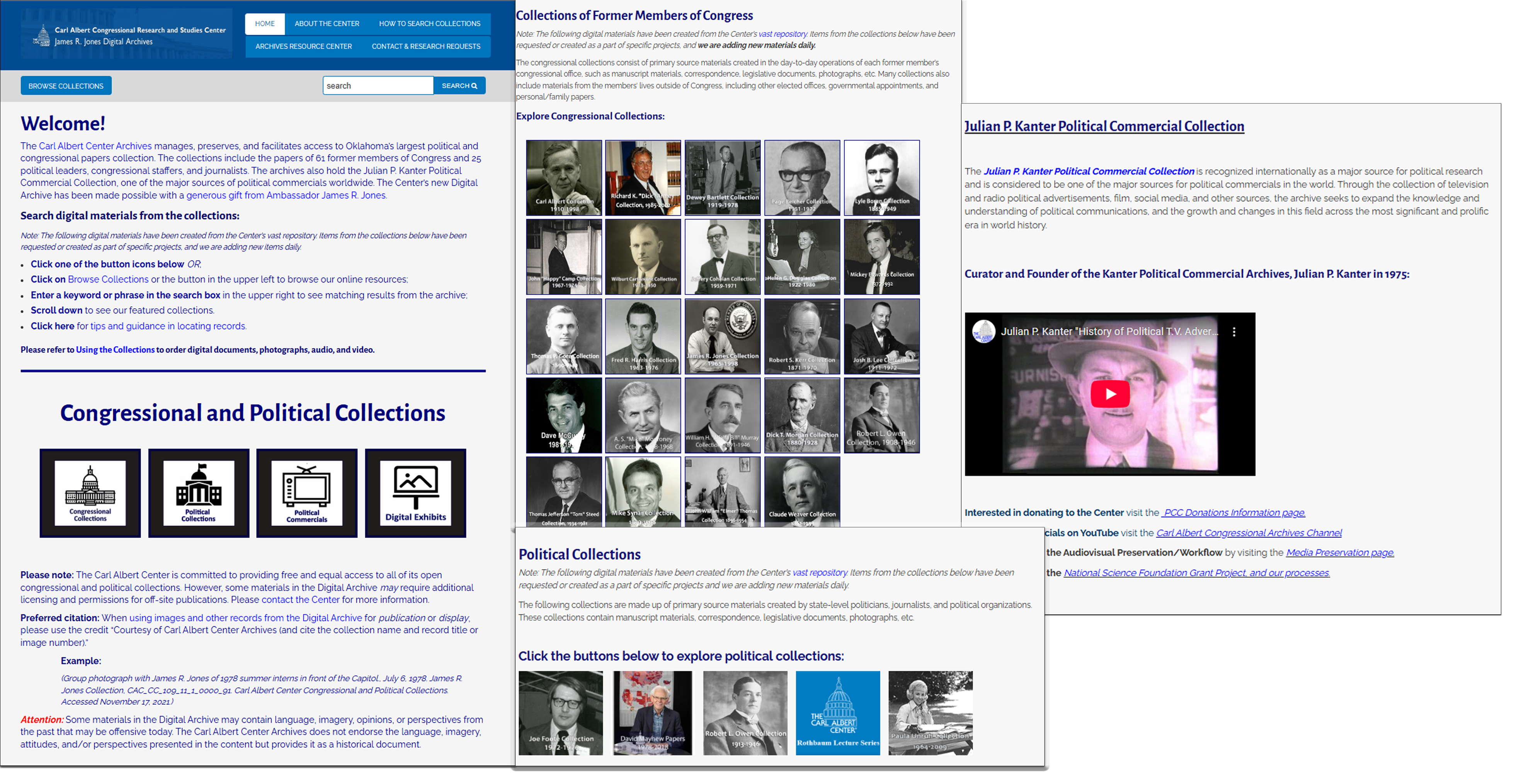
Related Links
- CAC ArchivesSpace
- CAC Digital Archives
- GitHub repository
- Related presentations and publications
- “Adaptive Learning Models for Efficient and Standardized Archival Processes” (2025)
- “Practical Remote Workflow Solutions for Complex Digital Projects: Opportunities in a Pandemic” (2021)
- “Oral History Interviews Data Curation Primer” (2020)
- “Carl Albert Center COVID-19 Curation Project” (2020)
- “The Carl Albert Photo Collection” (2021)